CS231N Lec. 10 | Recurrent Neural Networks
please find lecture reference from here1
CS231N Lec. 10 | Recurrent Neural Networks
Recurrent Neural Networks.
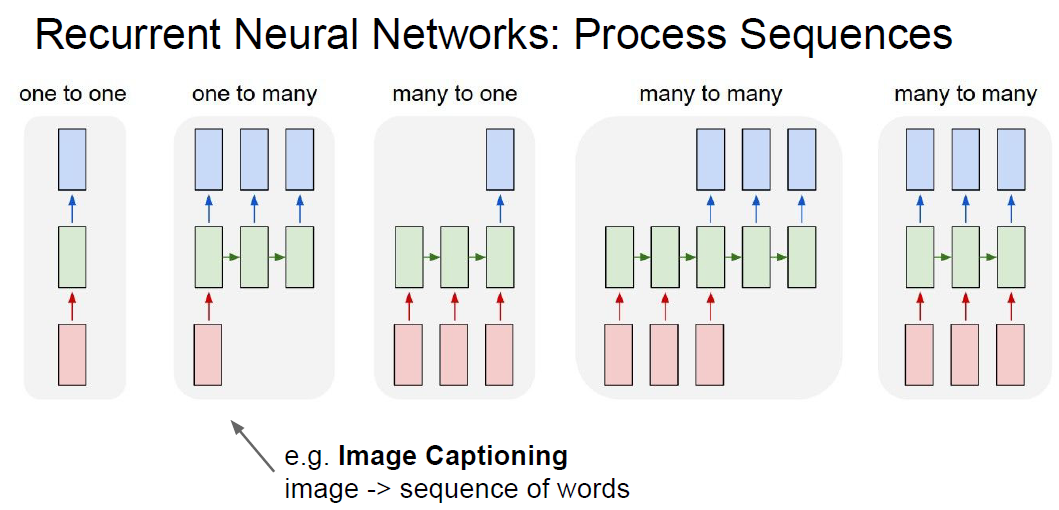
We could get more flexibility from RNN. More options for in/output data types.
- One to many
- image to sequenc
- Many to one
- Setiment classification
- Read Sentence sentiment
- Comprehense Video contents (variable frames)
- Many to many
- Machine Translation
- English -> Korean
- Many to many
- Video classification on frame level
But, RNN also useful fixed-size input like image. RNN could sequentially process non-sequential data. 
So, the concept of RNN would be this. 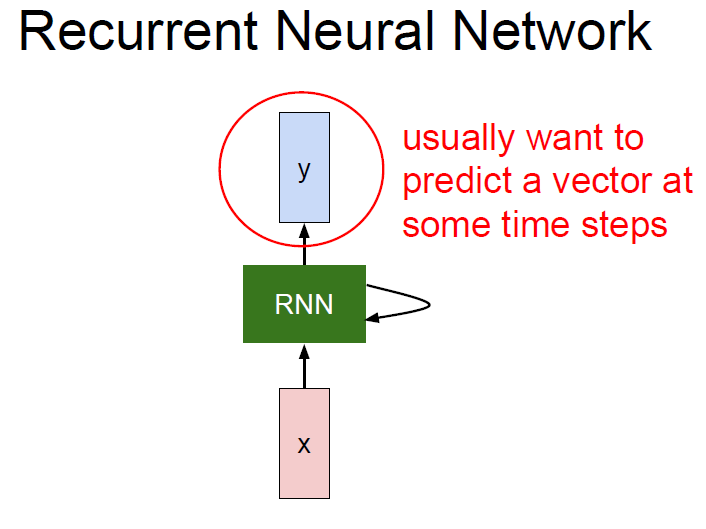
RNN formula.
Note: The same function(f) and the same set of param. are used at every time step. 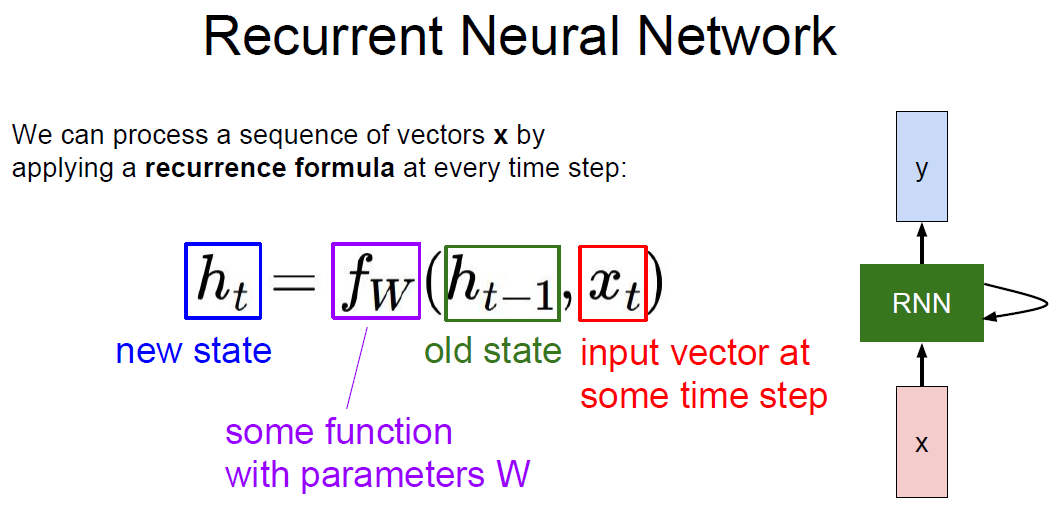
Vanlia RNN
Weight for prev. hidden layer(h_t-1) and input(x_t) 
RNN : Computational graph : Many to Many.
Unique h and x, but same Weight.
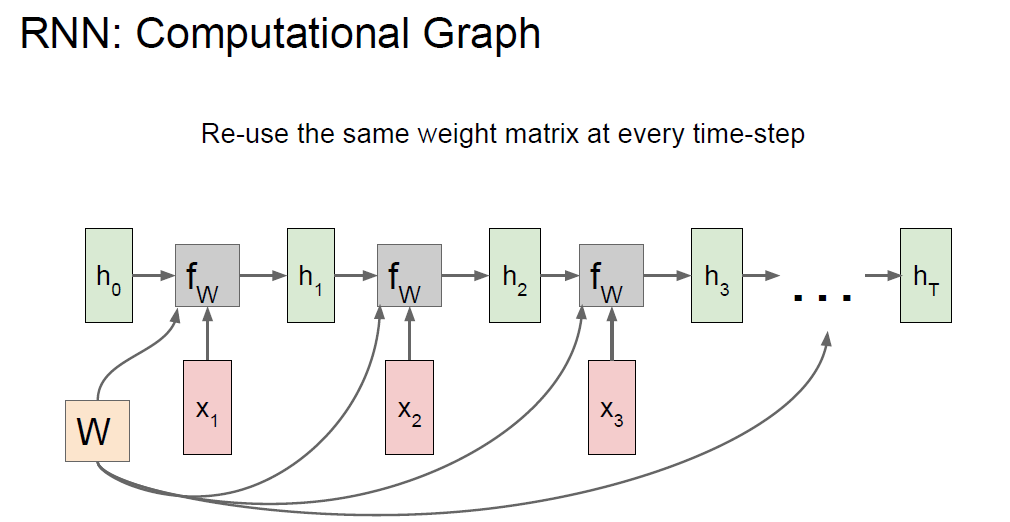
We can get loss per every time-step hidden layer. Total Loss would be sum of losses. 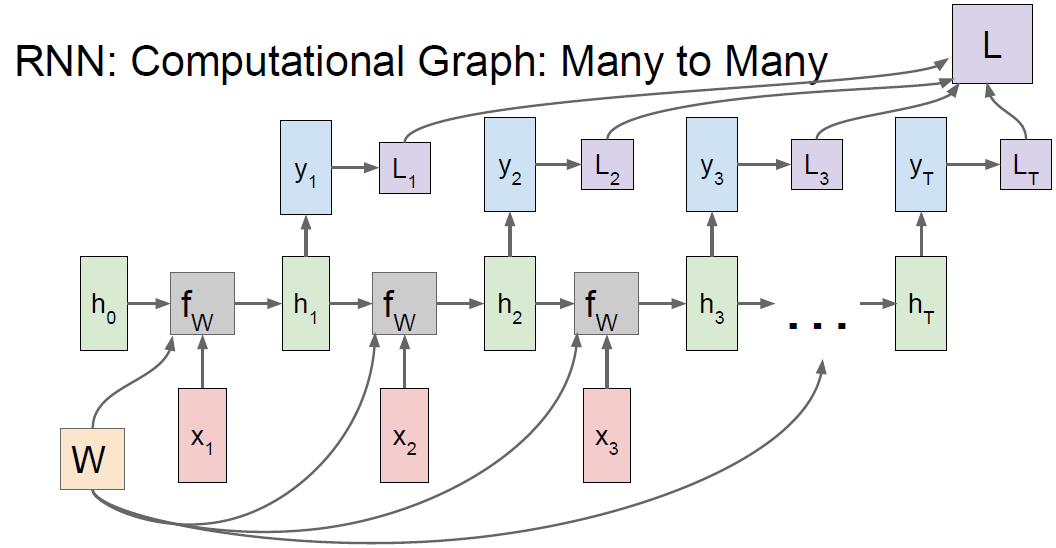
RNN : Computational graph : Many to One
e.g.) Sentiment 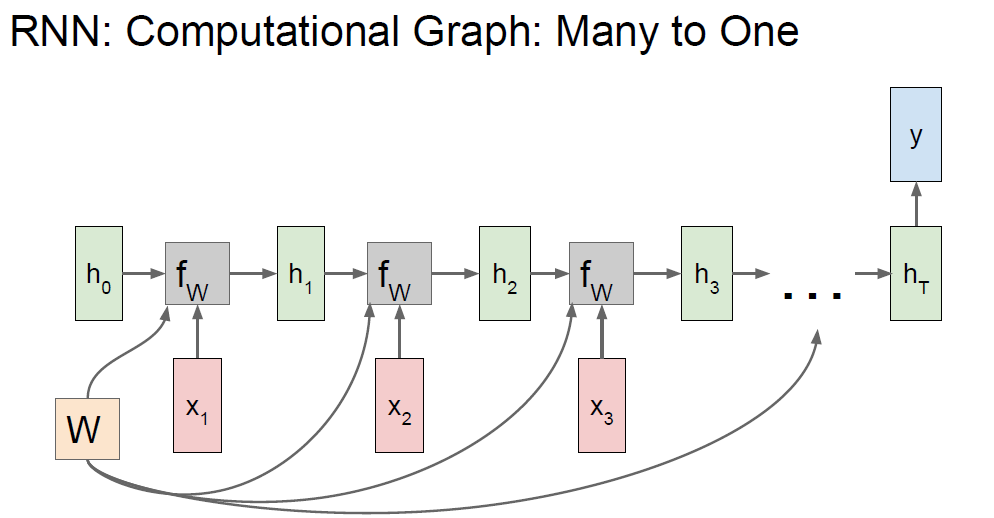
RNN : Computational graph : One to Many
e.g.) Sequential process of non-seq. data 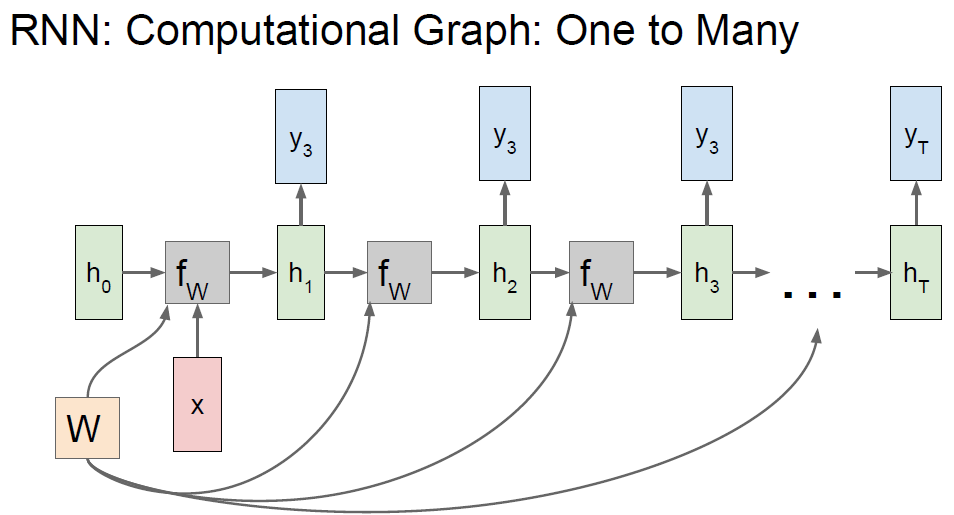
RNN : Computational graph : Many to One + One to Many
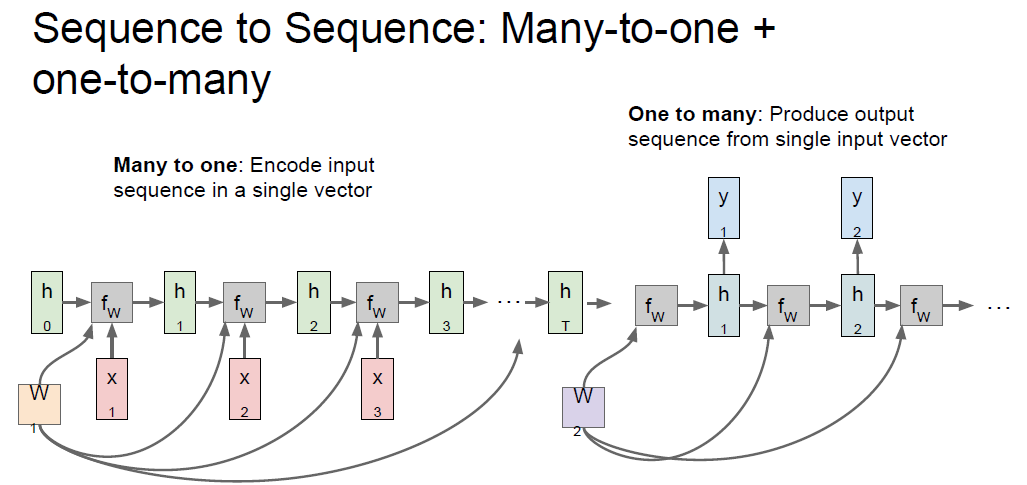
Example)
- Use input as each character for Vocab.
- Output is value of Softmax, to use probability distribution
By using probability distribution, we could get proper word “hello”. If we use argmax, much easiler, but couldn’t get proper answer.
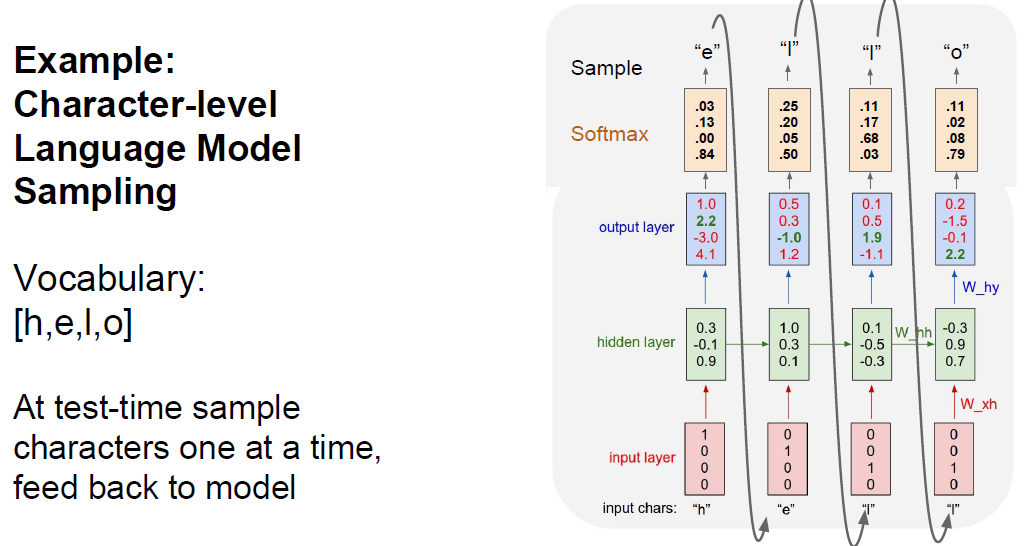
Q. Why use sample, instead of just taking argmax?
A. Good Question. As we can see above ex, if we take argmax, we couldn’t reach out answer. But in practice, both are useful. Sometimes argmax maybe stable. But, samplingg gives you diversity of modle.
But Problem is, too long test time for forward/backword through entire sequence to compute gradient. (image training entire Wekipedia) 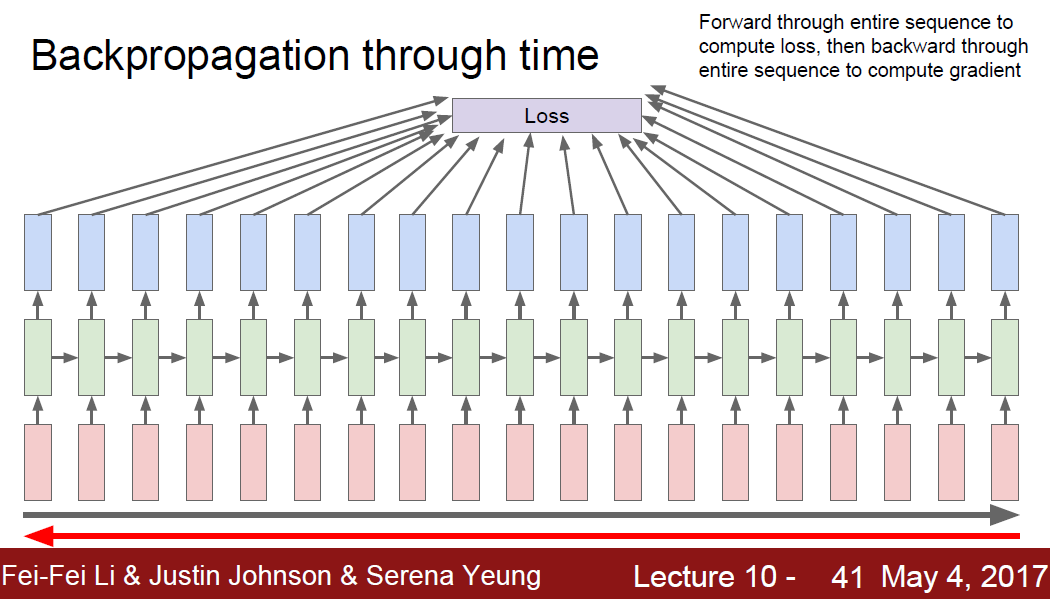
One Solution is, Truncated Backprop.
It’s approximation using minibatch, run forward/backword through chuncks of the sequence, instead of whole seq. 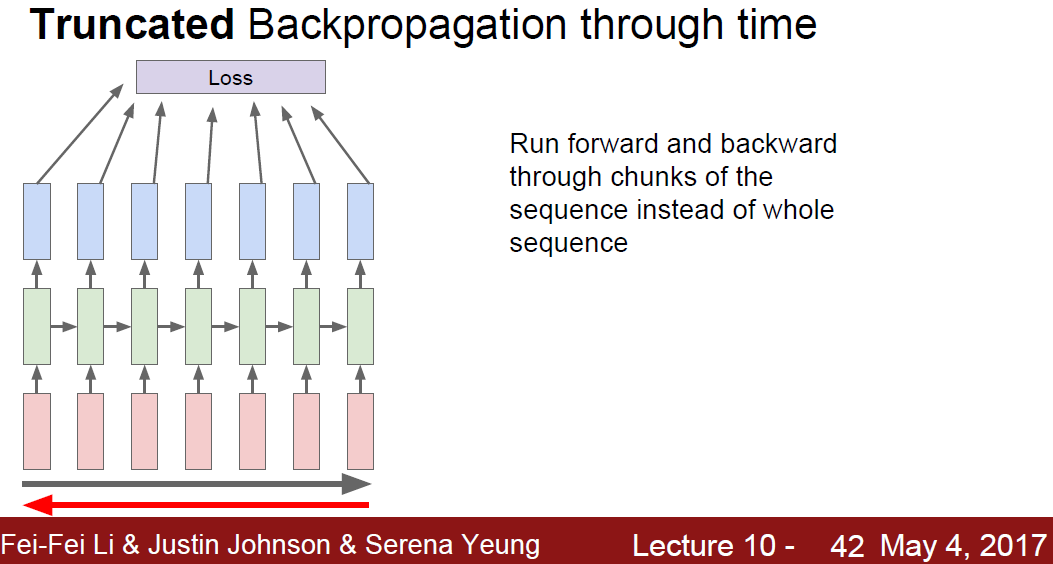
After 1st batch hidden layer, keep carrying them as forward. But backword, only use for some part of them. 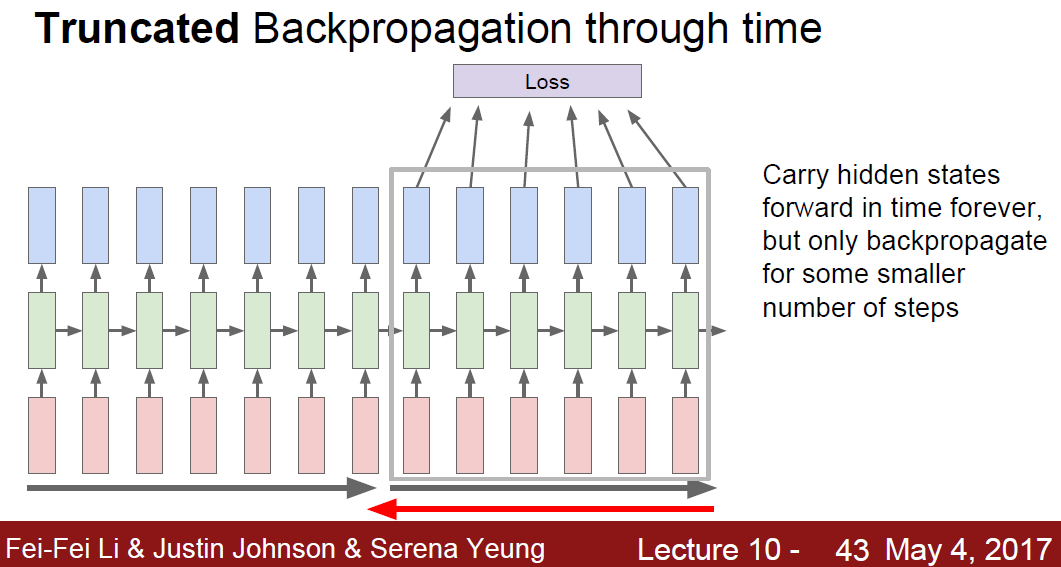
This contiuned to the end. 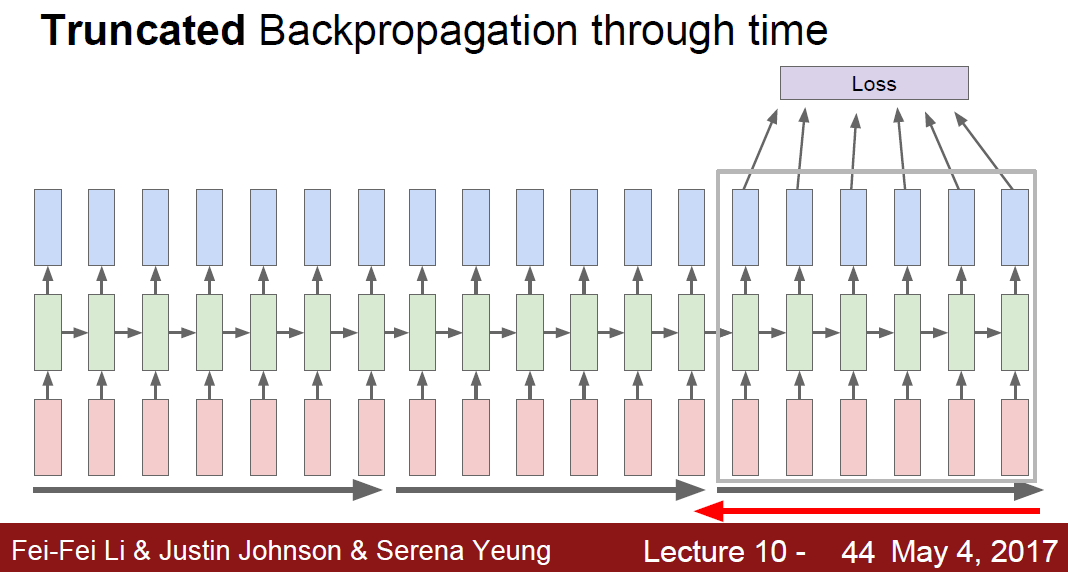
Q. Is this kind of “Markovian assumption2” ?
A. Nope, hidden state is all to predict the entire future.
Notable point is, it’s not difficult, implemented just 112 lines of python, find min-char-rnn.py from gist.
Rnn is powerful for NLP. After some train, model can say some nicer setences. 
Even play. 
Even Algebra topology…. 
Back to the image processing,
As we saw from one to many + many to one, we could apply CNN and RNN, makes model to say what image is. 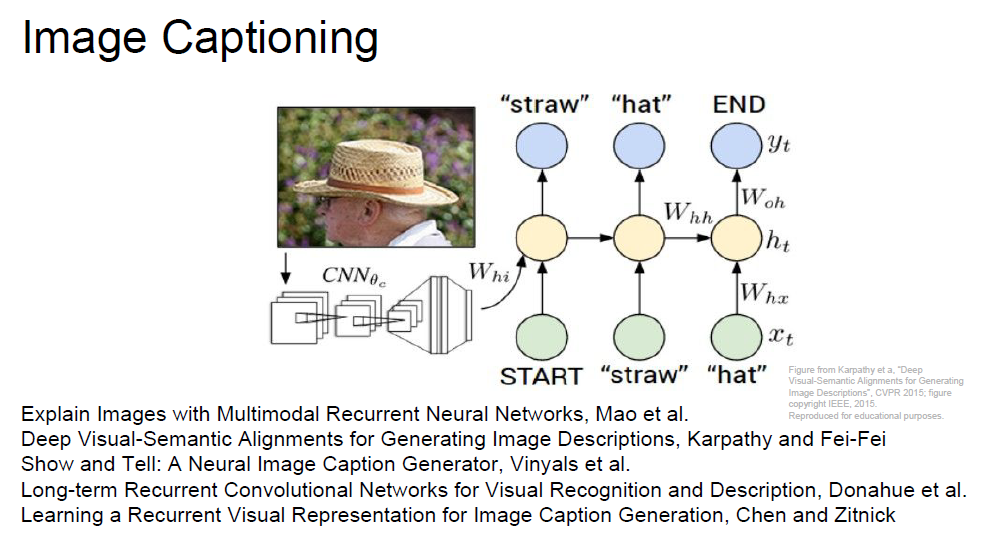
But low performance when if non-trained input comes. It’s not much easy to generalize. 
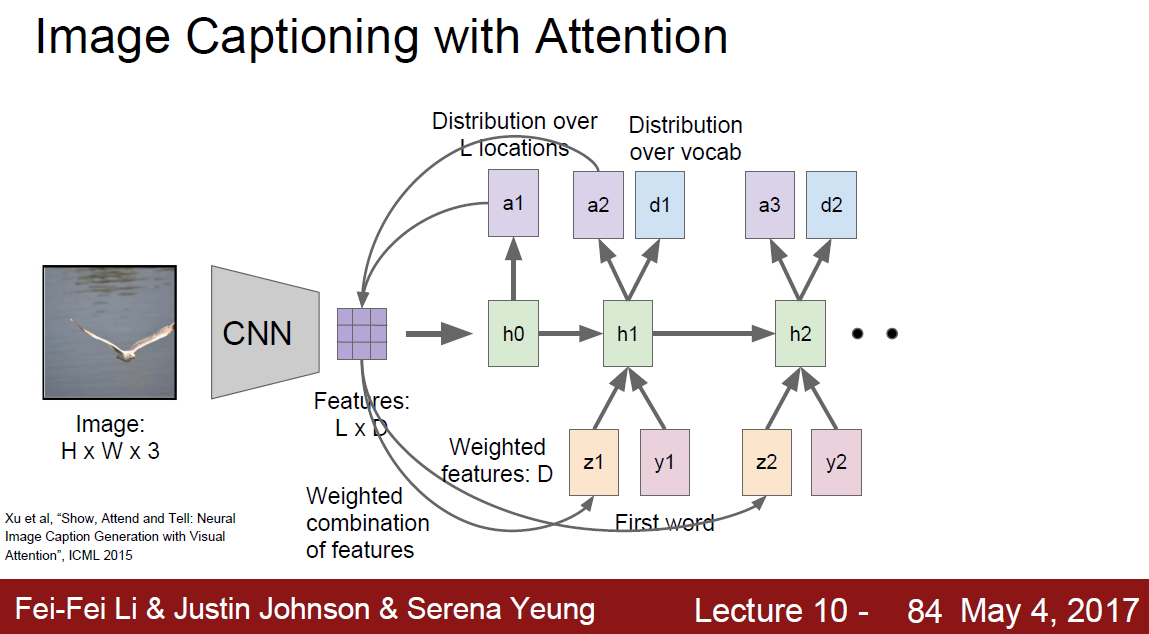
Image caption with Attention
- CNN output is a grid of vector
- Get location to get attention(a1). Calculate with CNN out vector, and feed to next hidden layer.
- Two outputs comes out.
- Distribution over vocab words.
- Distribution over image location.(location to get attention)
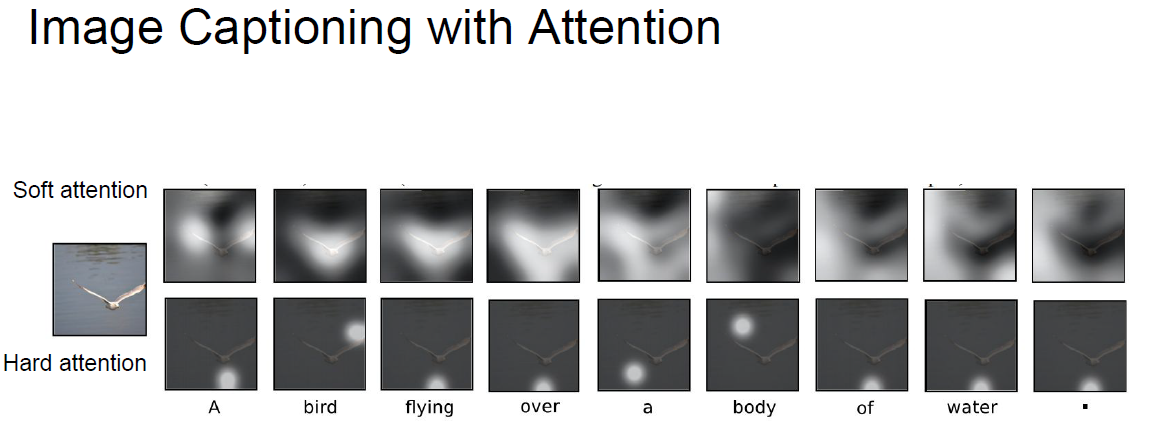
Soft / Hard attention
- Soft
- Attention could be any of image location.
- Hard
- Force model to look at one location of image.(related to reinforce learning)
RNNs with Attention could be a good method for Visual Question Answering. 
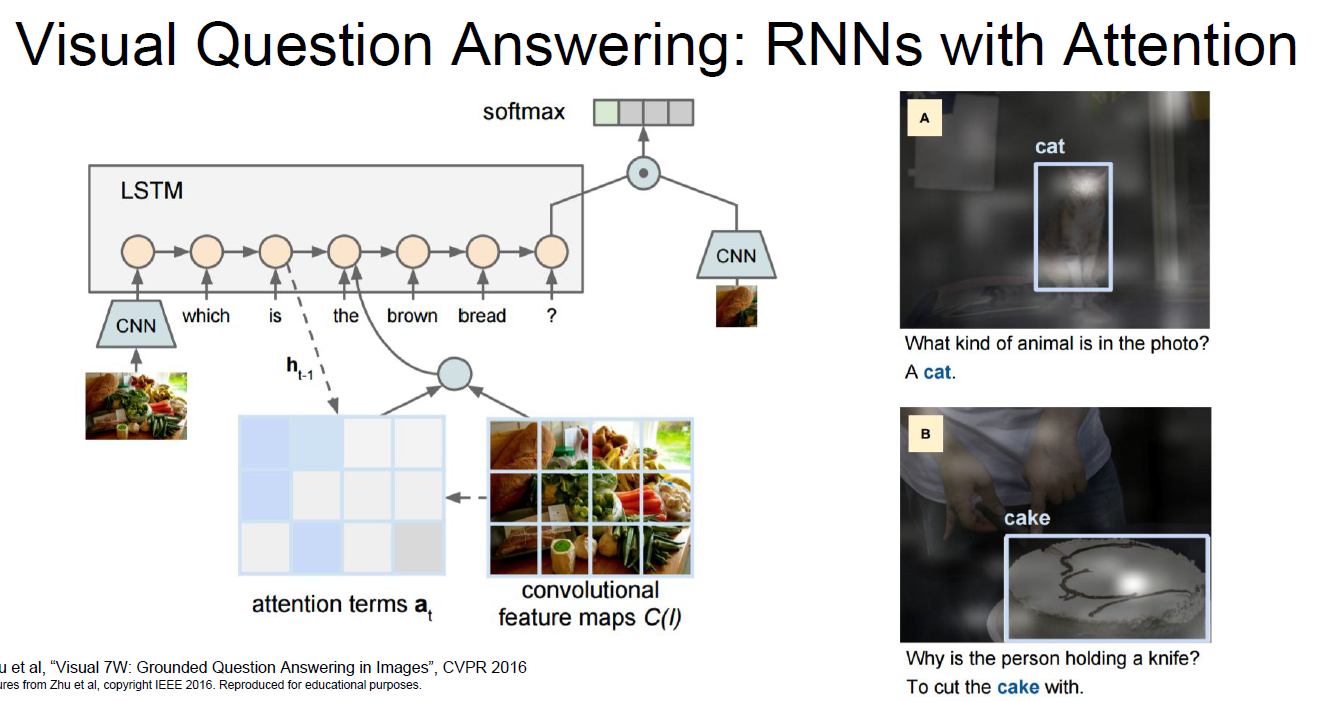
Q. How to use two different inputs(question/image)
A. Usually concatenation used firstly and it’s powerful. Other multiplicative interactions also used.
We’ve studied single-layer RNN, but usually multi-layer RNN used. But not deep, just 2~4 layers are typical. 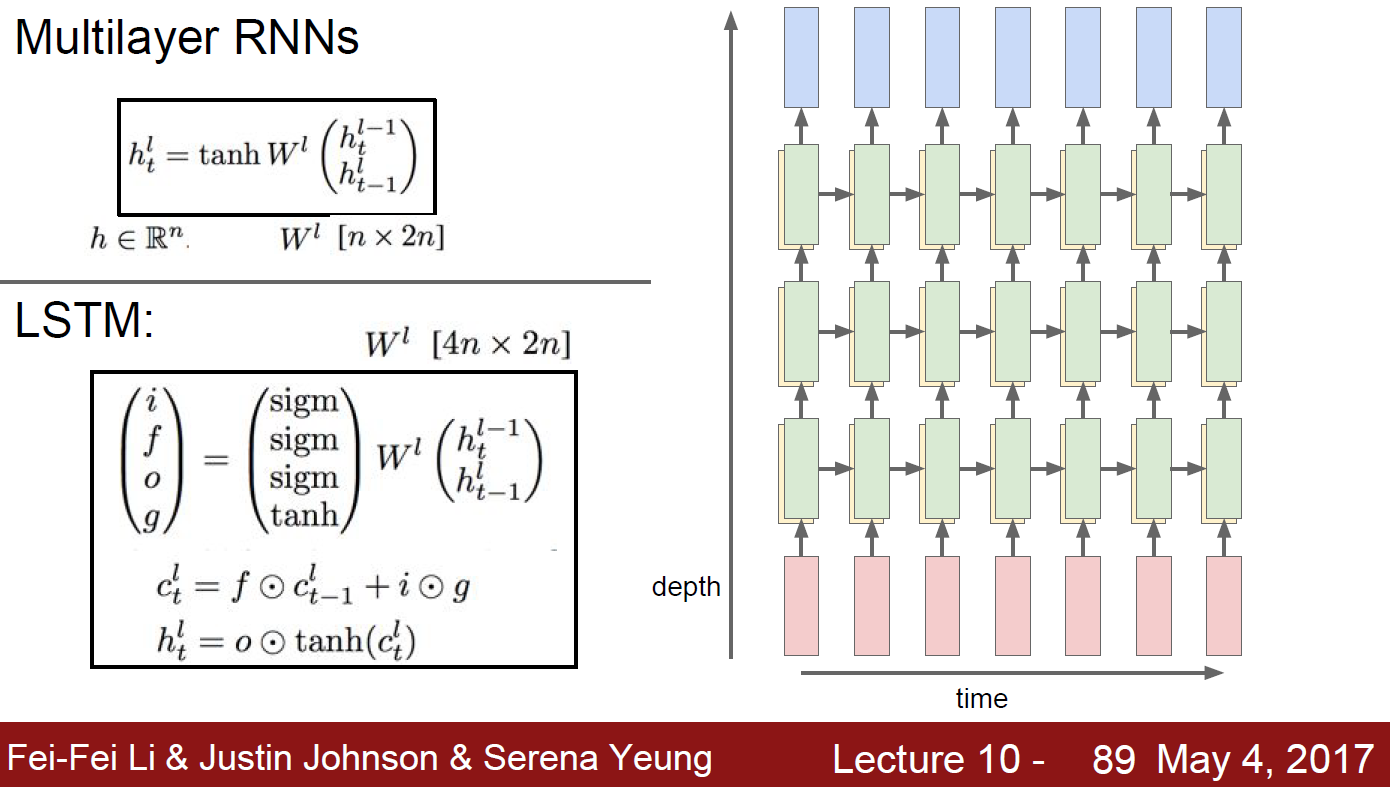
Gradient of Vanilla RNN
Let’s consider gradient of vanilla RNN. As we saw before, gradient of matmul results into multipling Transpose of Matrix. 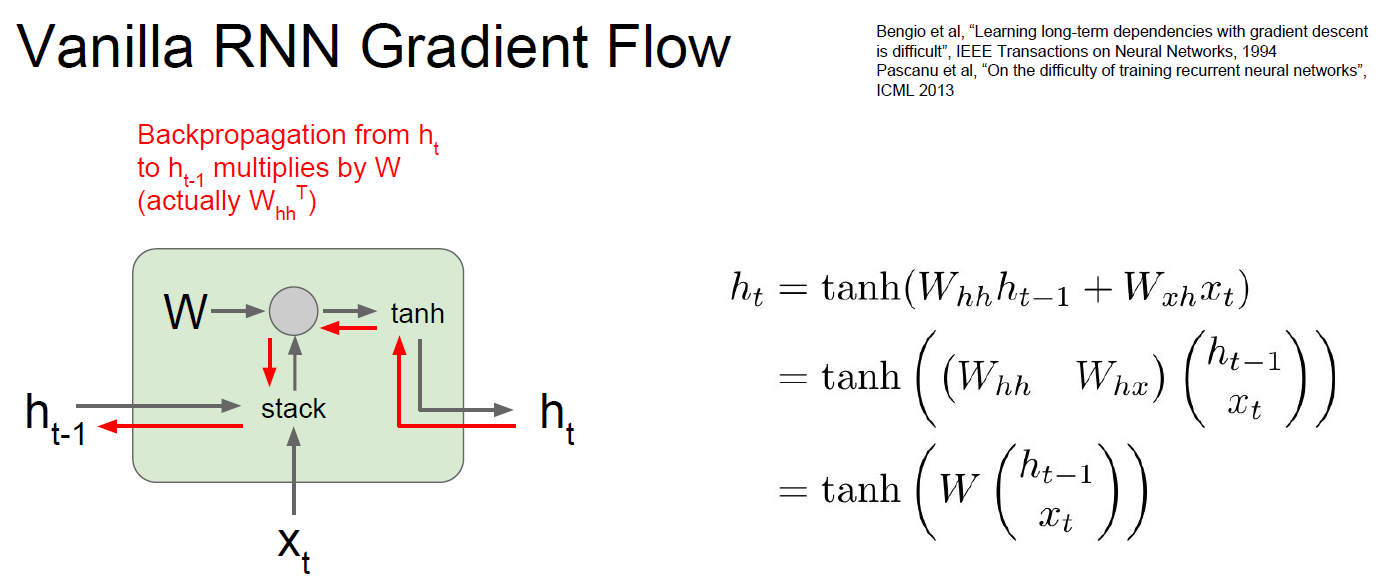
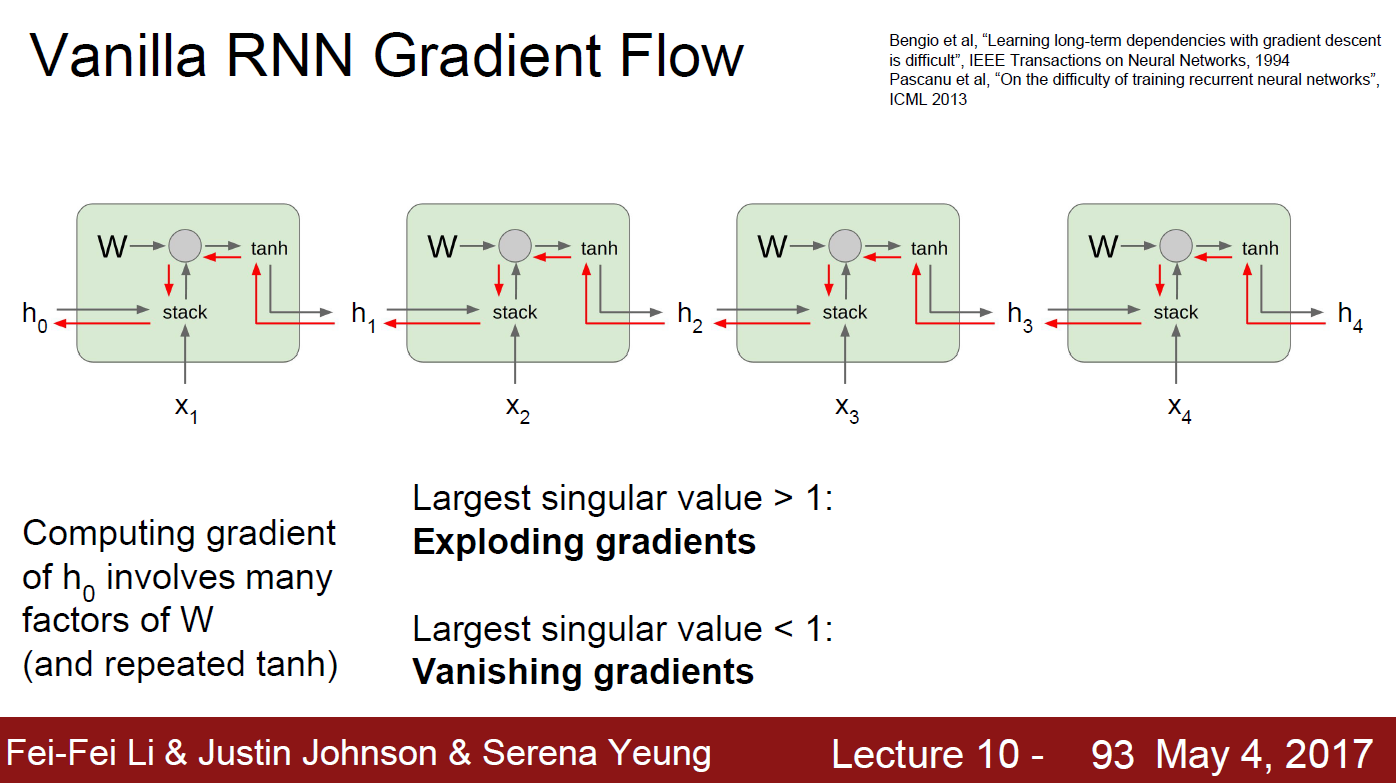
If we consider multiple RNN layers, there should be multipling same W repeatedly ( because RNN have same W ).
Let’s assume W matrix as scalar and infinite layers to think easier. In this condition,
- if W > 1, then exploded.
- if W < 1, then vanished. only W = 1 would be only way to not happend aboves, but should be rare to happen. Same intuition applied to Matrix
- if Largest singular value > 1, then exploded.
- Divide grad into grad_norm. (gradient clipping)

- if Largest singular value < 1, then vansihed.
- Change RNN architect
- LSTM(Long Short Term Memory)
LSTM (Long Short Term Memory)
T-story(kor) was helpful.
Many flow charts and diagrams are exist to explain LSTM. This time, Let’s believe Standford. 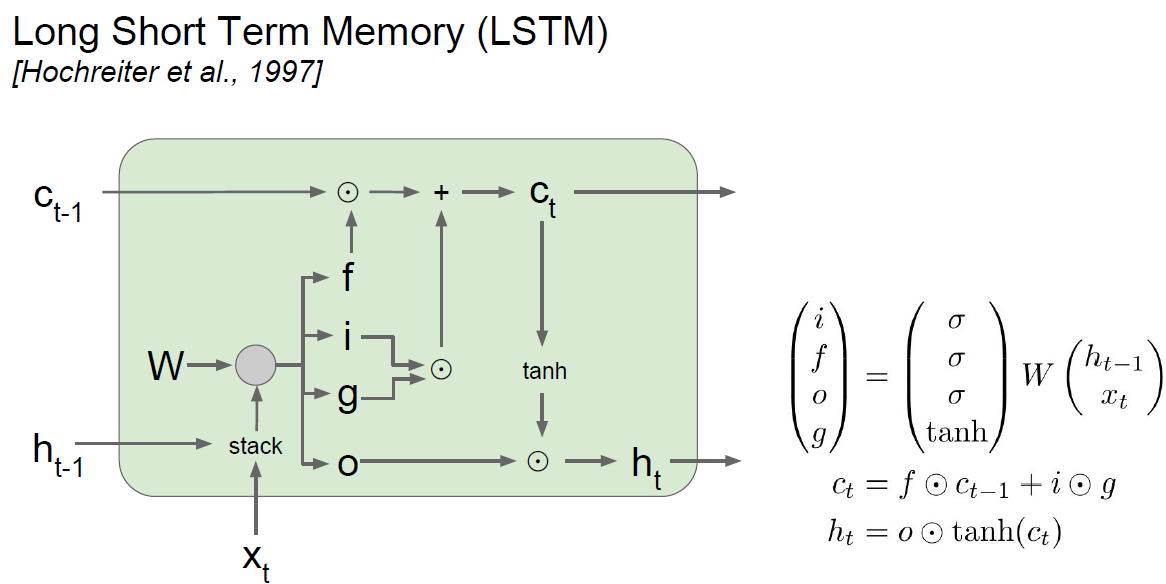
- f : Forget gate
Whether to erase cell - i : Input gate
Whether to write cell - g : Gate gate
how much to write to cell - o : Output gate
how much to reveal cell
LSTM In backward pass
As we know, in Vanila LSTM backprop., mutlply same W was main problem.
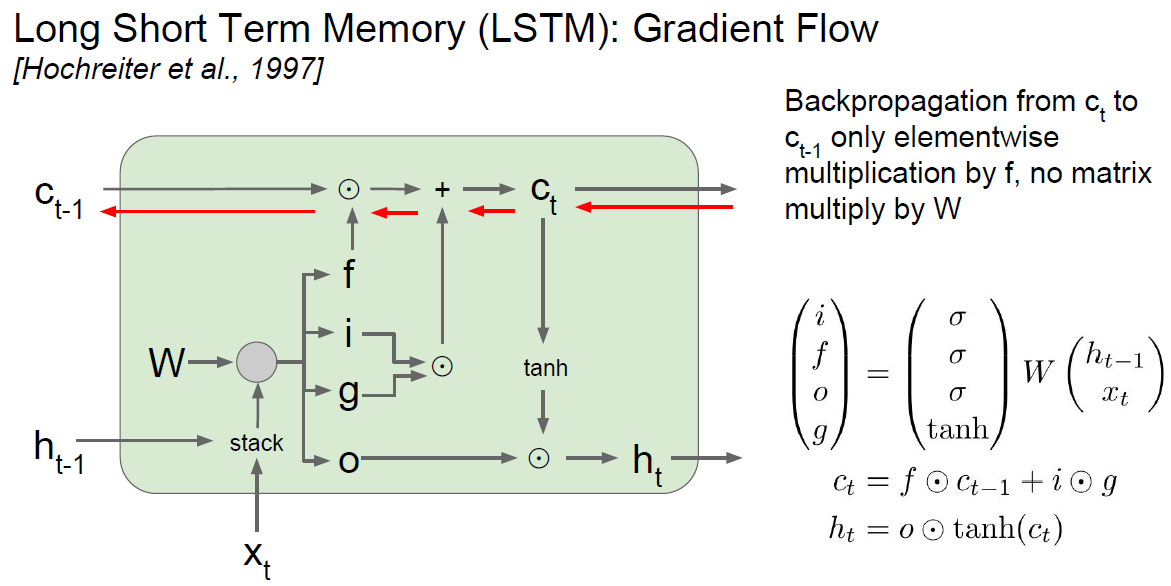
Other RNNs
GRU, LSTM : A Search Space Odyssey, … 
GRU(Gated Recurrent Unit)
GRU is simplied version of LSTM. 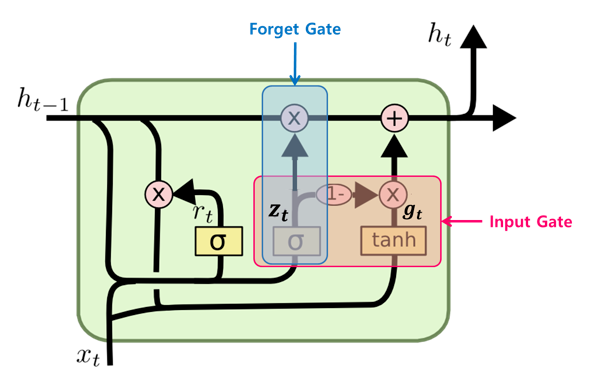
Summary
- RNNs allow a lot of felxibility in architecture design.
- Vanilia RNNs are not that usefull.
- Commonly LSTM / GRU used : additive interactions improve gradient flow
- Backprop. of RNN can explode/vanish.
- Explode : controlled with gradient clipping
- Vanish : controlled with additive interaction(LSTM)
- There’s a lot of nice overlap between CNN and RNN architecture.
Lecture(youtube) and PDF ↩
A stochastic process has the Markov property if the conditional probability distribution of future states of the process (conditional on both past and present states) depends only upon the present state, not on the sequence of events that preceded it. from Wiki ↩
