CS231N Lec. 9 | CNN Architectures
please find lecture reference from here[^1]
CS231N Lec. 9 | CNN Architectures
CNN Architecture
Today lecture is about CNN Architectures. 
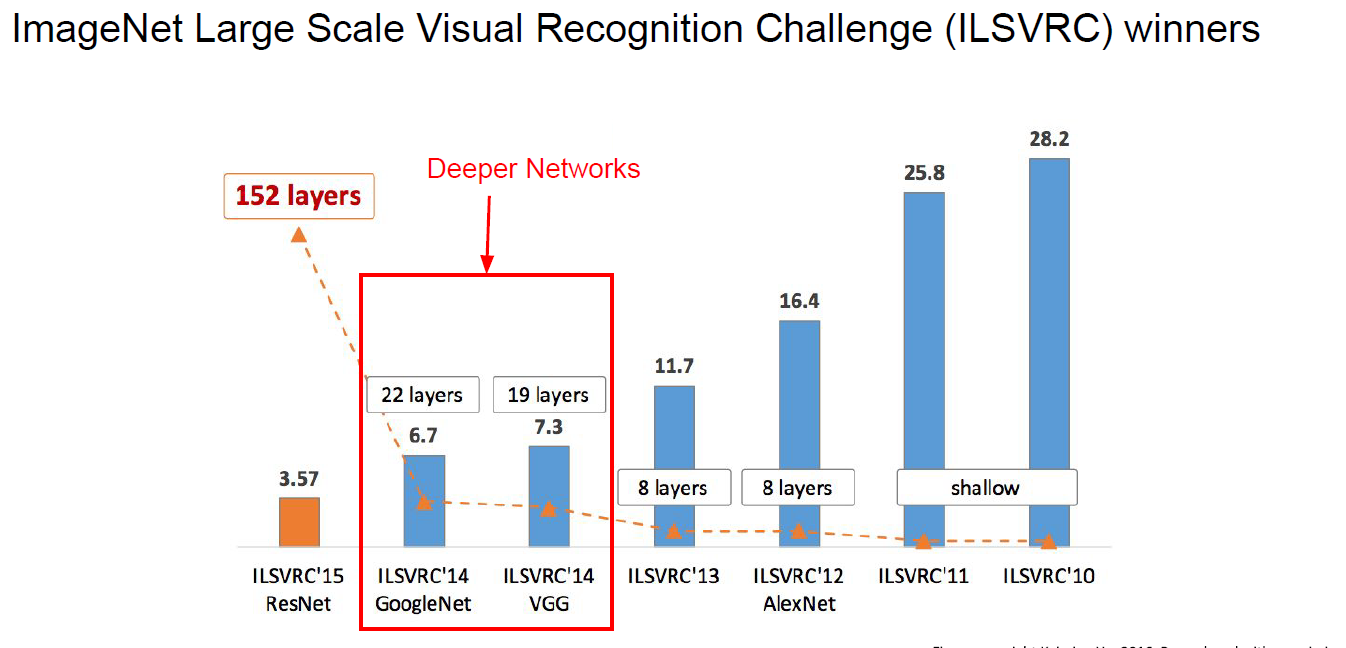
AlexNet
Let’s start with AlexNet ( with quiz )
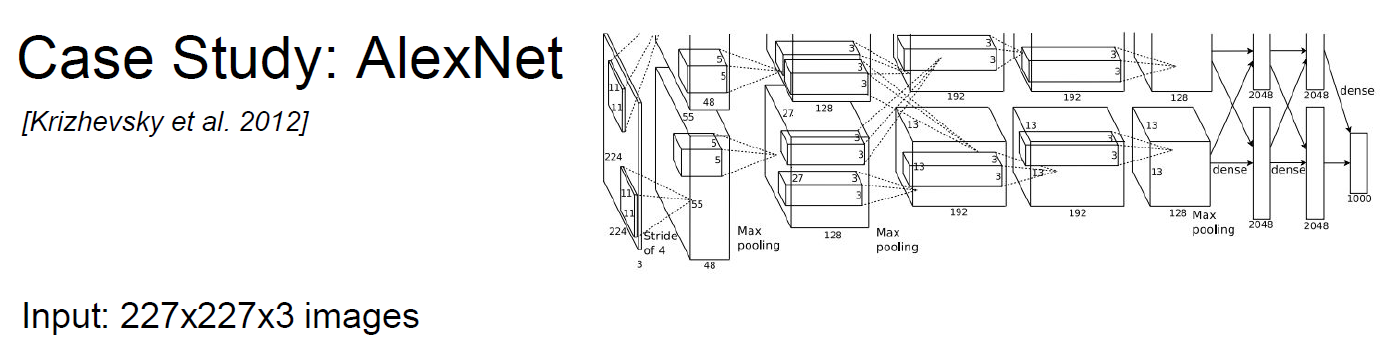
Q1.

Answer is, 55 x 55 x 96 (W_out x H_out x Num-of-filters)
Q2.

Answer is, (11x11x3)x96 (W-filter x H-filter x input-depth)xNum-of-filters
Q3.

Answer is, 27x27x96 (W_out x H_out x Num-of-depth)
Q4.

Answer is, 0 !! (Because it’s pooling layer, nothing to learn. )
Historical Note
At 2012, traine was done at GTX580(quite old GPU), which only have 3GB memory. so divide neuron into half, and learned at each GPU. 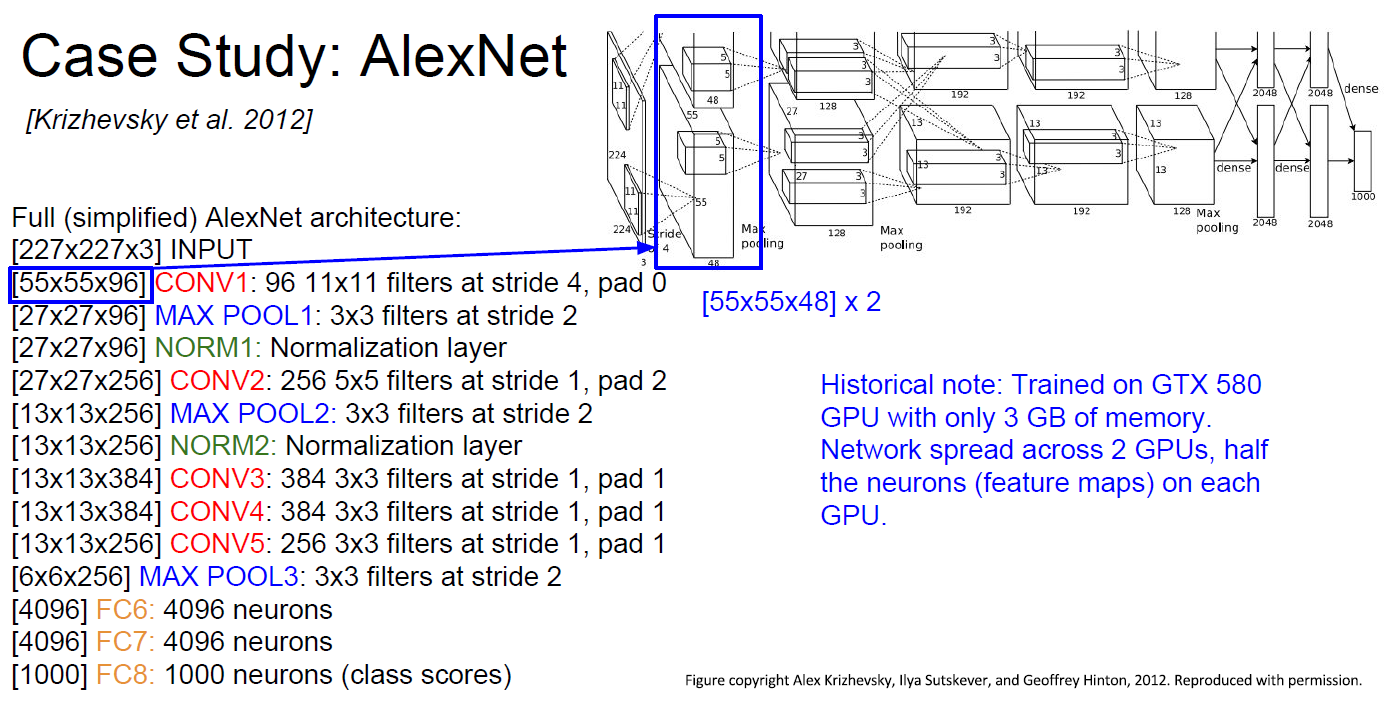
Achievement
AlexNet is 1st winner of CNN-based network at 2012.
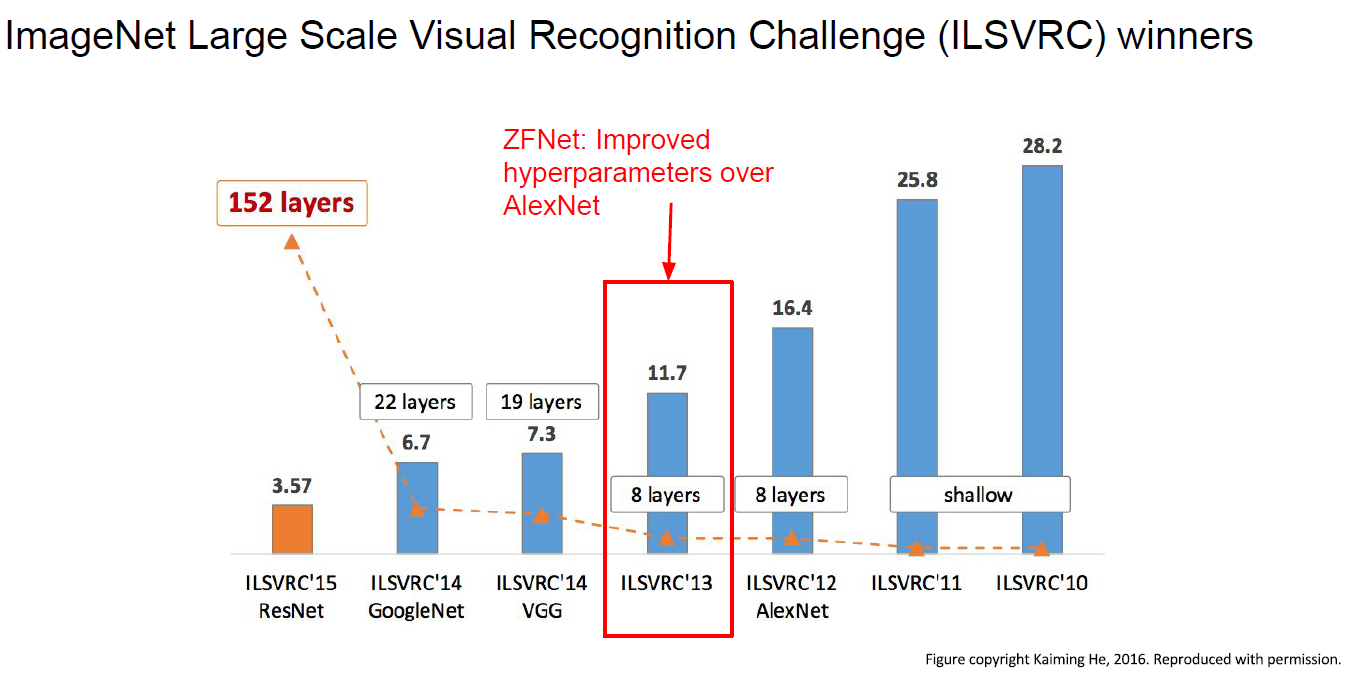
GoogleNet and VGGNet
Deeper! Better! ( than AlexNet )
VGGNet
Smaller filters, Deeper networks.

Q1. 
A1.
With smaller filter, we could have deeper network. three (3x3) conv (stride 1) layers has same effective receptive field as one (7x7) conv layer.
Q1-1. 
A1-1.
Answer is [7x7].
At every coners of [3x3] looks another [3x3], so, becomes 3->5->7. 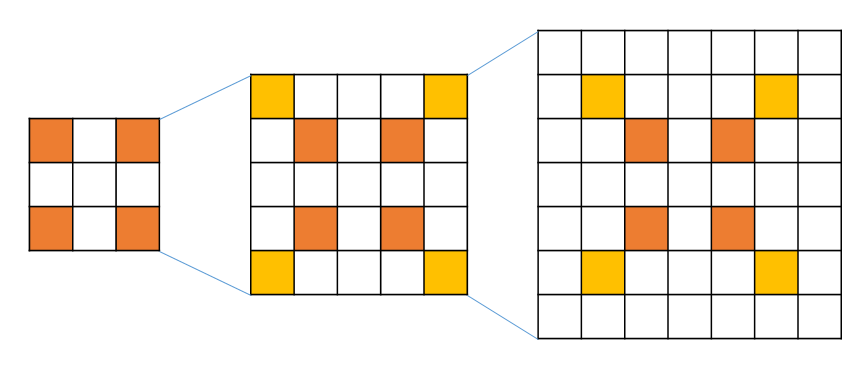
So, by using smaller filter, we can get deeper and more non-linearities.
And, fewer params : 3(3^2C^2) vs. 7^2C^2
(C : input depth, total number of output feature map*)
So the result would be like below: 
Q. For each layer, what do different filters need?
A. Each layer means, one feature map, one activation map of all the responses of different spatial location. Each filter correspond to a different pattern that we looking for in the input.
Q. Intuition for deeper network, more channel depth, more number of filters ?
A. Deeper network is not mandatory. One reason is, relatively constant level of compute. Another reason is, when you go deeper, usually you’ll use down sampling, which is less expensive to make deeper network.
Q. I don’t think we should memorize all of the data, we could throw away some parts.
A. Yes, some are we don’t need to keep. But we also need to save for further backprop.. So the large part of them need to save.
GoogLeNet
Deeper networks, with computational efficiency.
Characteristic point of GoogLeNet is, network of network(Inception Model). 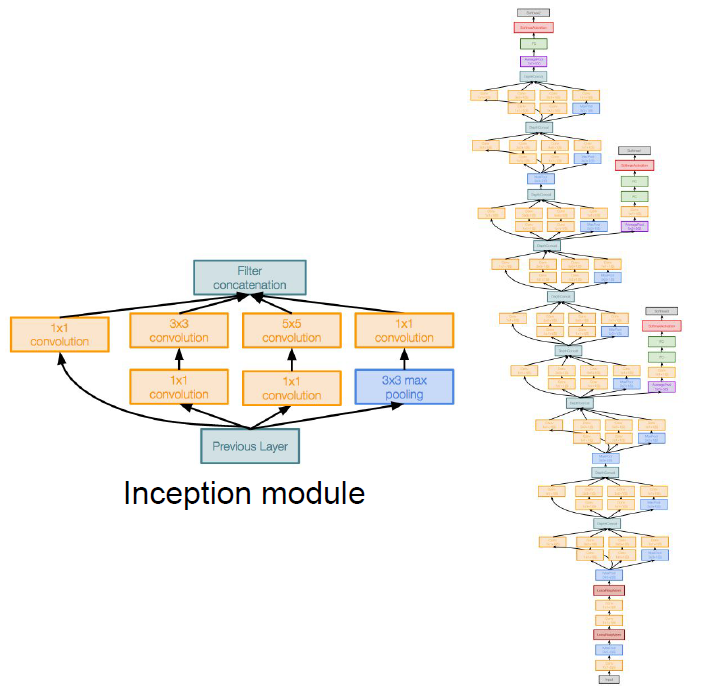
Appling parallel filter operation on the input from previous layer.
- Multiple receptive field sizes for conv. (1x1, 3x3, 5x5)
- Pooling (3x3)
And then, concate all filter outputs together depth-wise.
Q. What is the problem with this ?
A. Computational complexity.
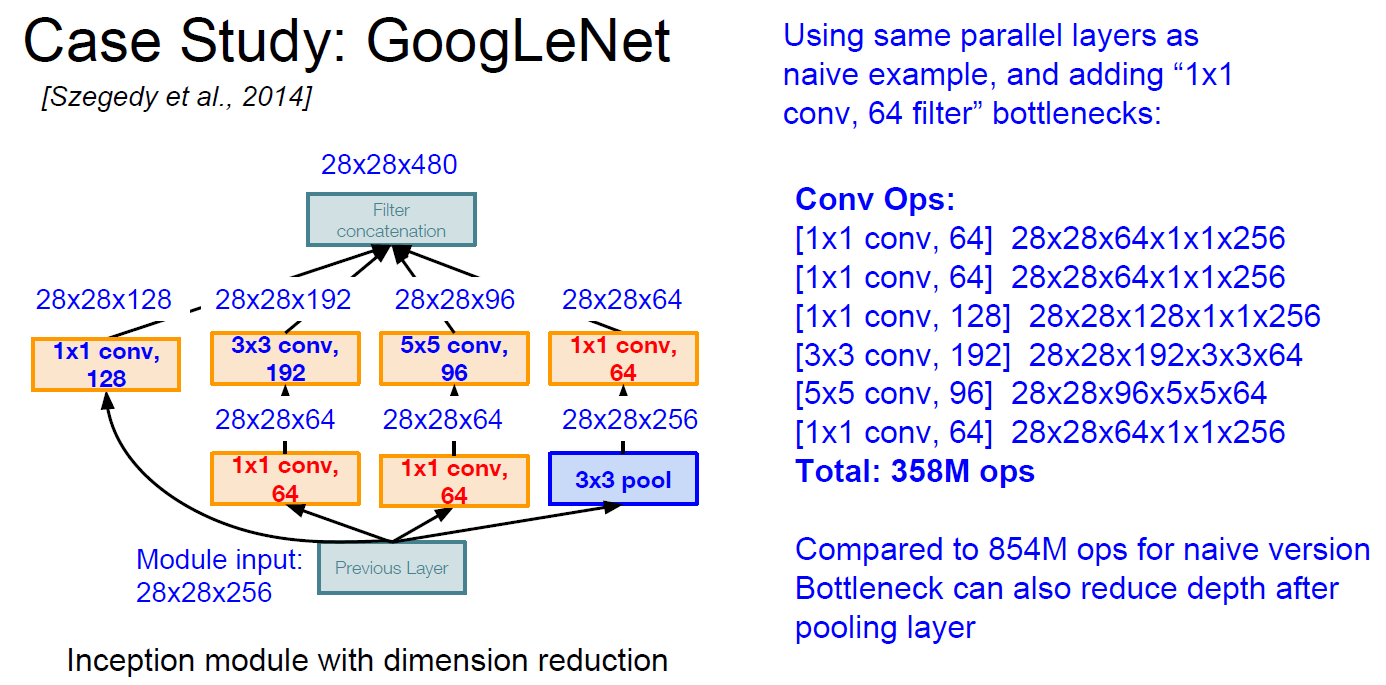
e.g.) let’s see naive implementation of googlenet.
By Zero padding, we could get all same Width & Height with different depth. And at concat. filter, adding all depth. 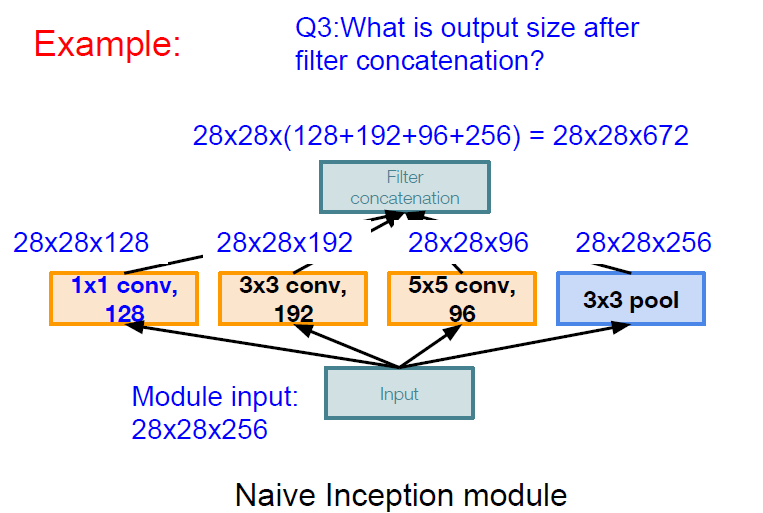
Quite expensive cost ! 
Solution : bottleneck !
With 1x1 CONV, we can preserve spatial demensions, with reduced depth.
So, the GoogLeNet would be below: 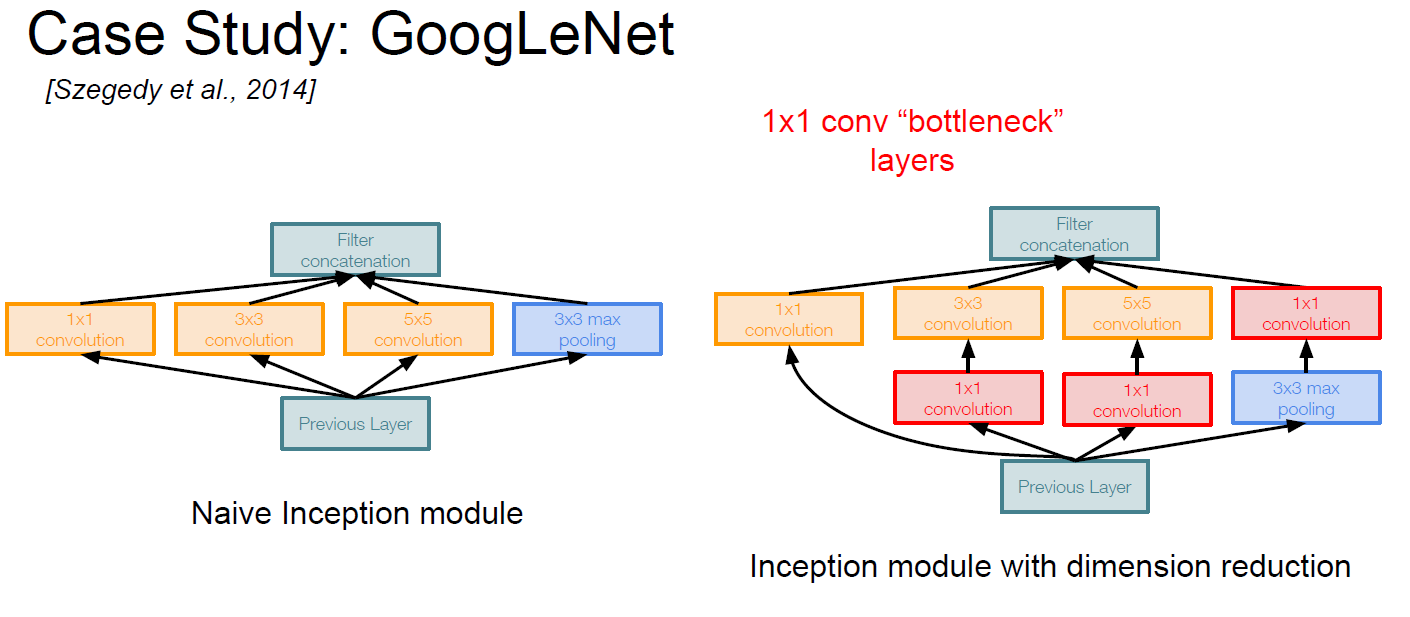
With 1x1 CONV (bottleneck)
- Operation reduced 854M –> 358M (-58%)
- Depth reduced 672 –> 480 (-29%)
Full Version of GoogLeNet. 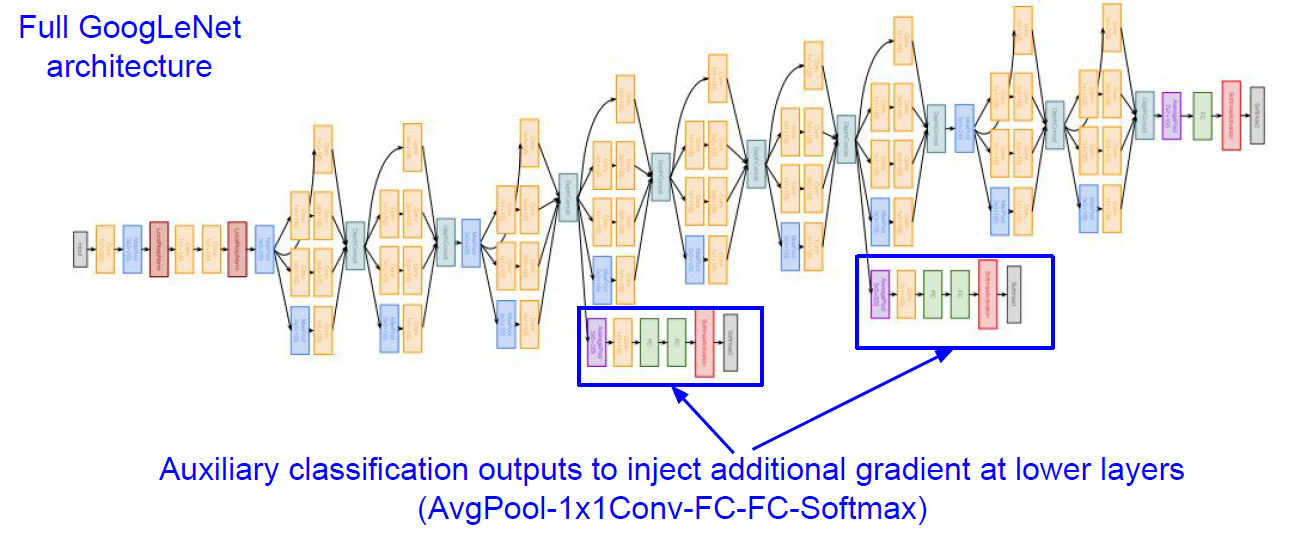
Q. Does auxiliary layer actually make better results? A. Yes, but you’ll need to check details.
Q. Can i use non-1x1 CONV at bottleneck? A. Yes, but benefits by reducing will be decreased.
Q. All of layers are sepearted W? A. Yes.
Q. Why adding auxiliary outputs to inject gradient?
A. When layers going deeper, some signals can be vanished. This can be helped by provide additional signal(auxiliary outputs)
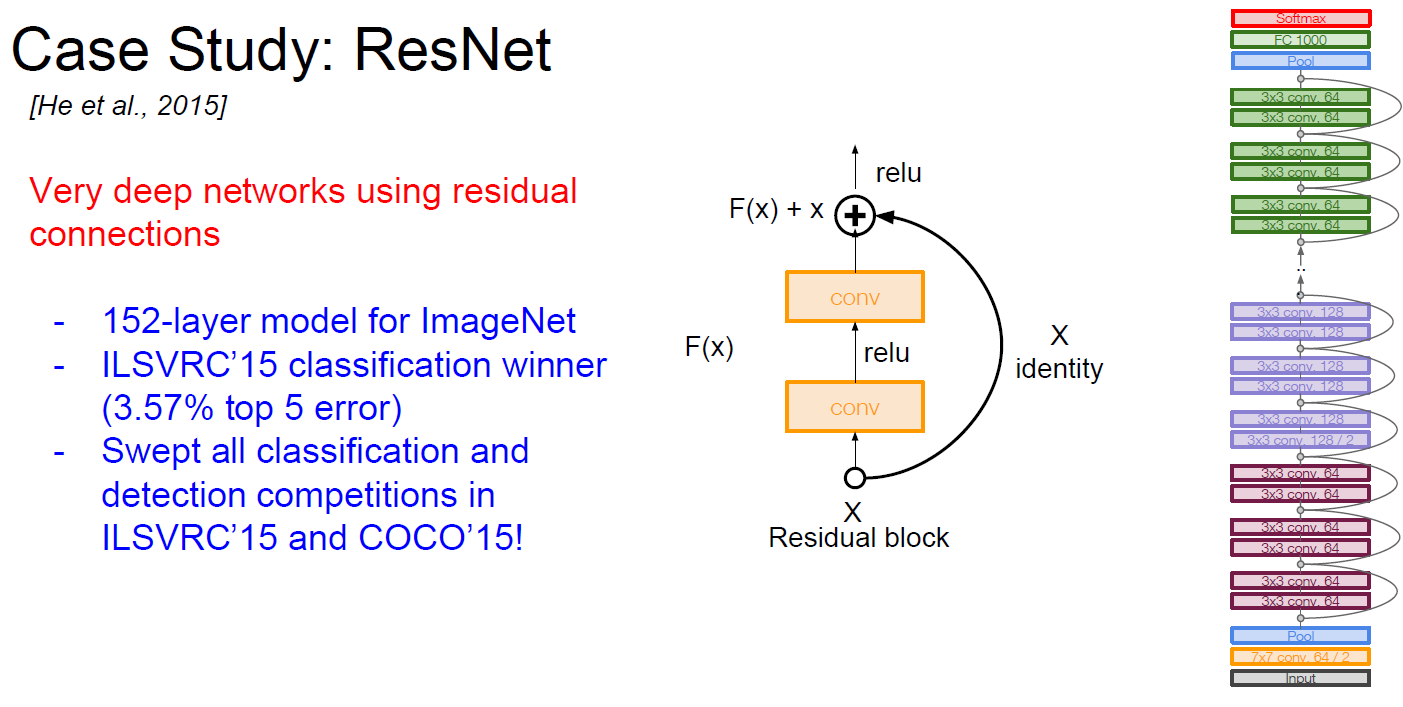
ResNet
Revolutionary deep networks using residual connection.
Let’s compare ‘plain’ deep vs shallow CNN.
As you can see at below graph, 56-layer performance worse. ( But it also worse for Training, so no matter of overfitting. ) 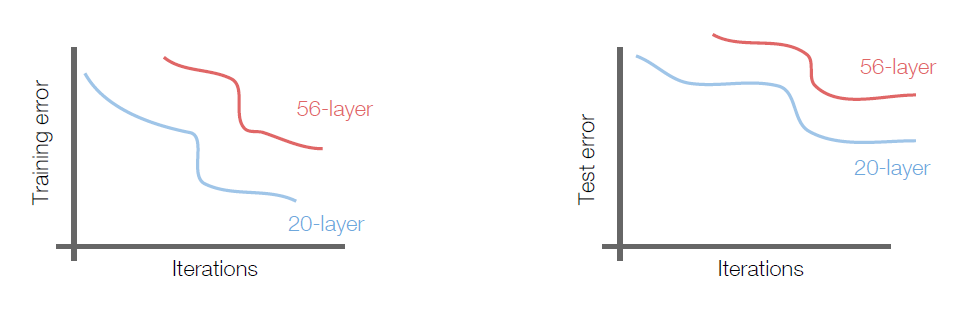
Following hypothesis is, the problem is an optimization problem. Deeper models are harder to optimize(cuz have more param.)
A solution by construction is copying the learned layers from the shallower model and setting additional layers to identity mapping.
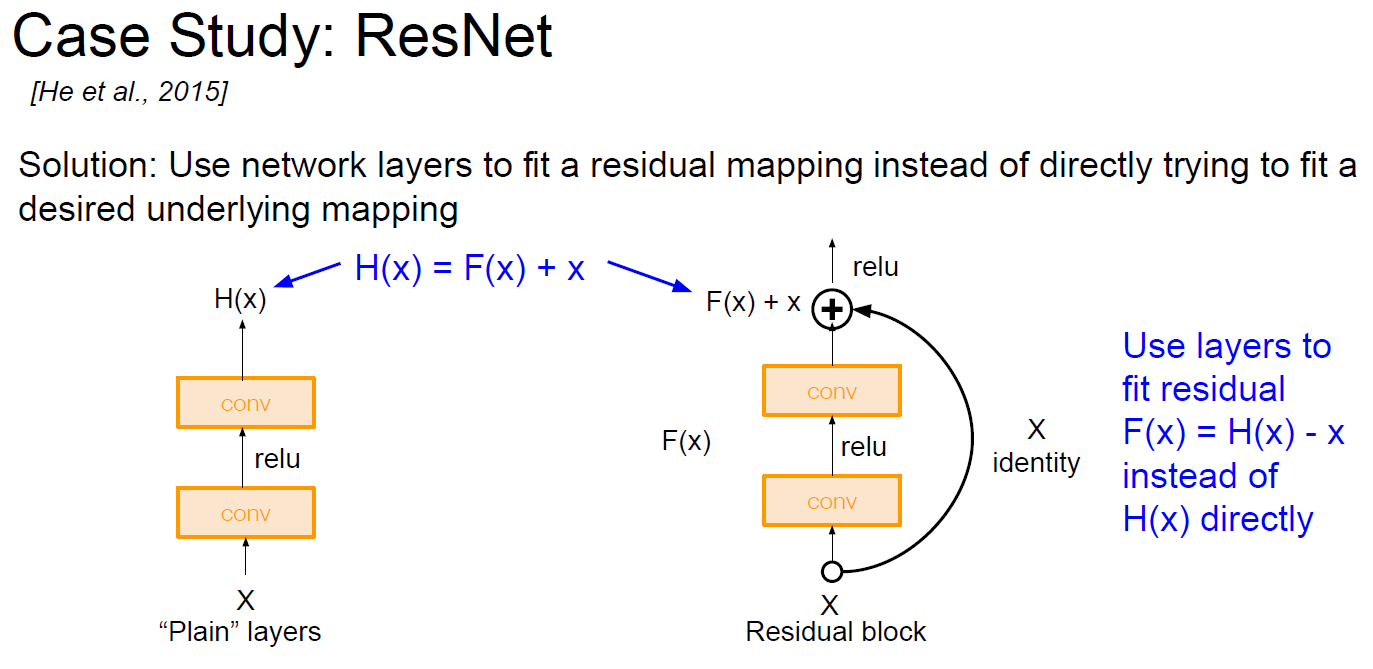
So the concept is, generally, Initial(shallow) learned layer would be good.
- Make Initial-learned-layer. (should fine and not deep)
- Make deeper layers by identity mapping, which would maintain Initial-learned-layer. (because hypothesis implies good-final-layer should not much different with Initial-learned-layer)
- Make model learn the identity. (if init-learned-model is best, F(x) would be zero, and seems much easier to learning. Because learning to not different with identity.)
- Finally get better score of Initial-learned-layer.
Therefore, i could summarize ResNet as
- Make good “Initial-learned-layer”.
- Go deeper, but try to learn “Initial-learned-layer”.
!! But mind that aboves are just hypothesis of ResNet !!
ResNet used “BottleNeck” in case of deeper network more than ResNet-50. 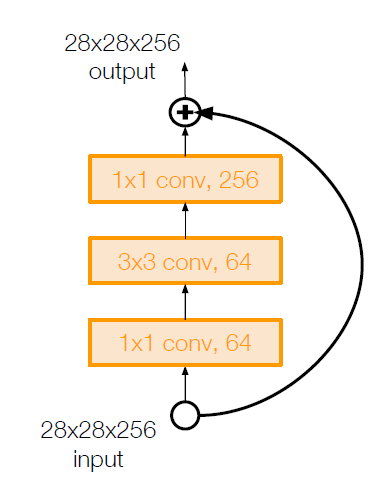

Other architectures
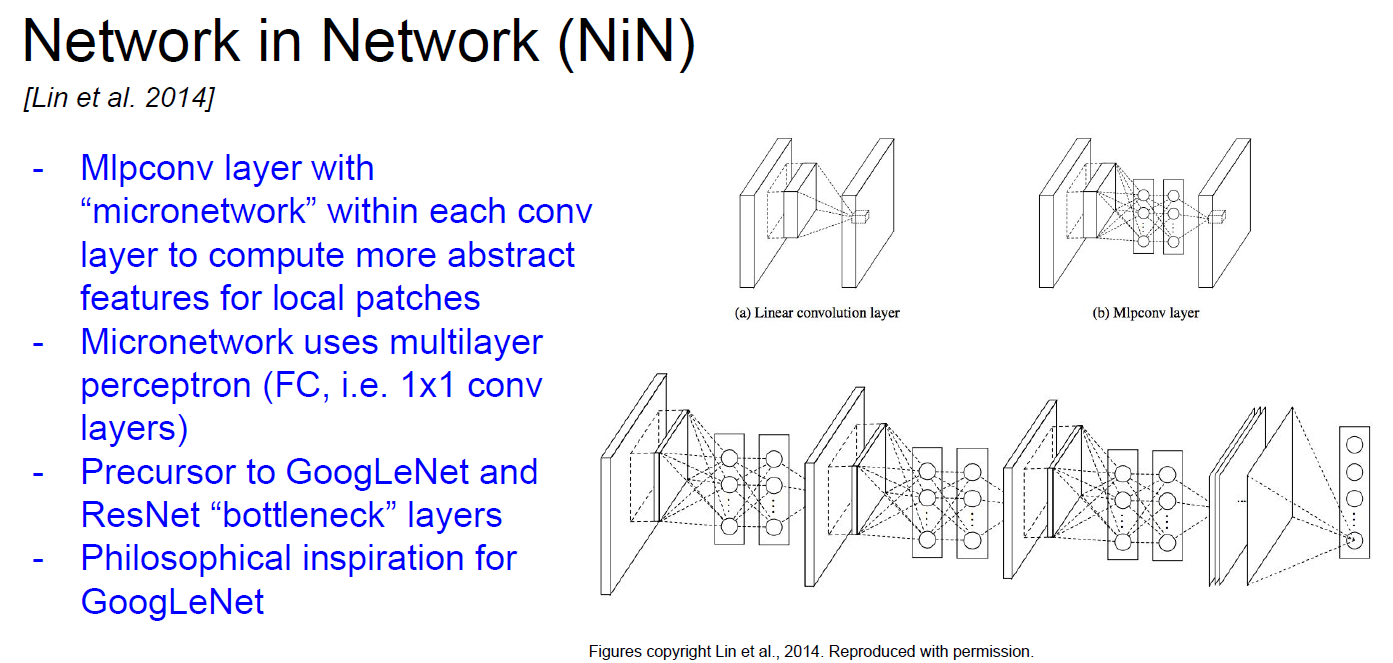
Network in Network (NiN)
- precursor of bottleneck of GoogLeNet
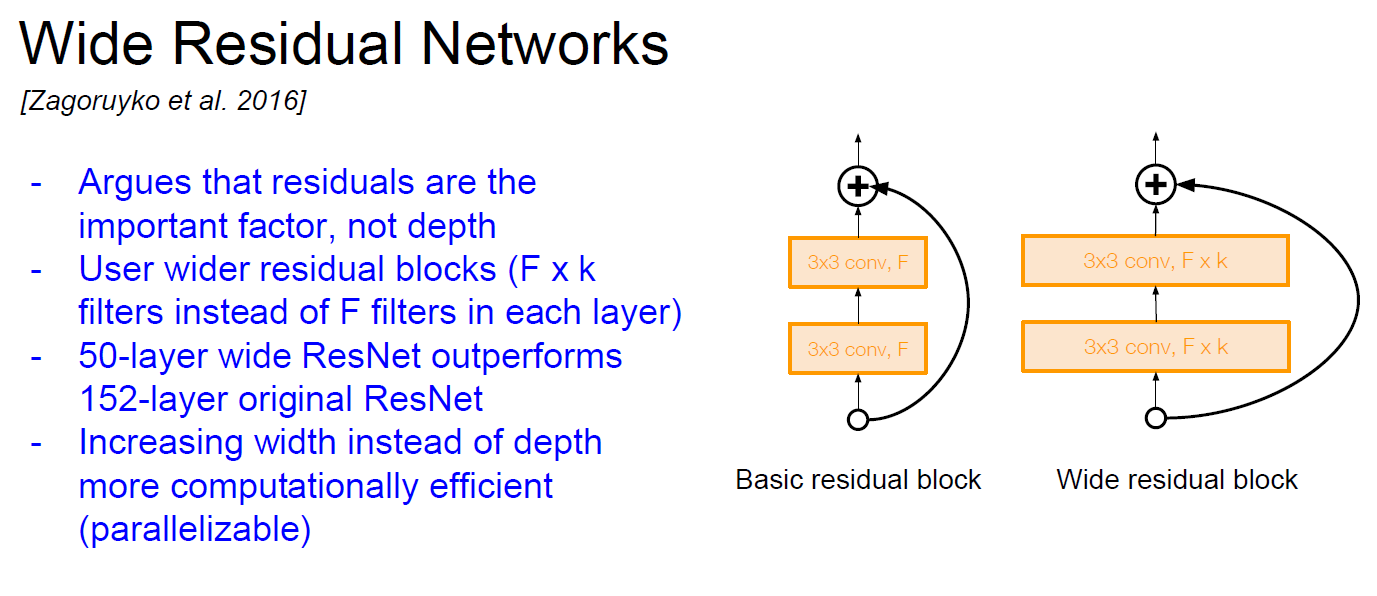
Wide Residual Networks
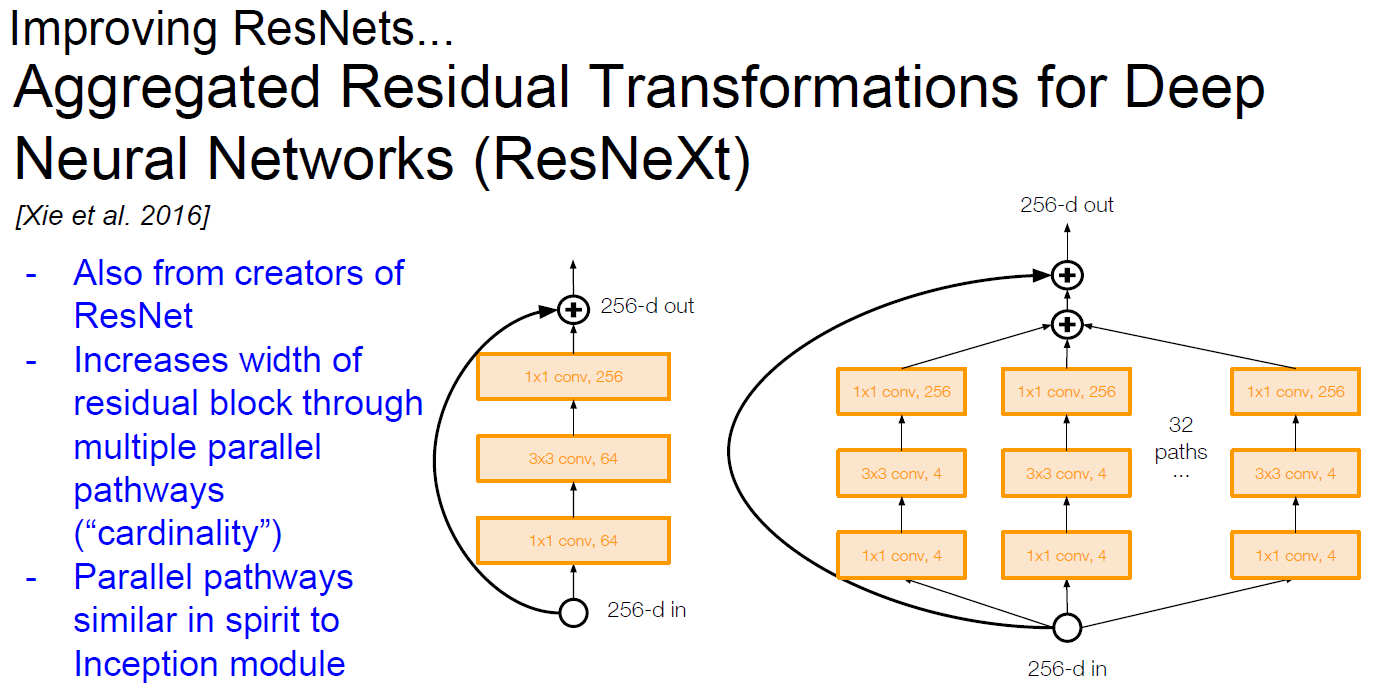
ResNext
Deep Networks with Stochastic Depth

FractalNet : Ultra-deep Neural Networks w/o Residuals
Argues that key is transitioning effectively from shallow to deep and residual representations are not necessary. 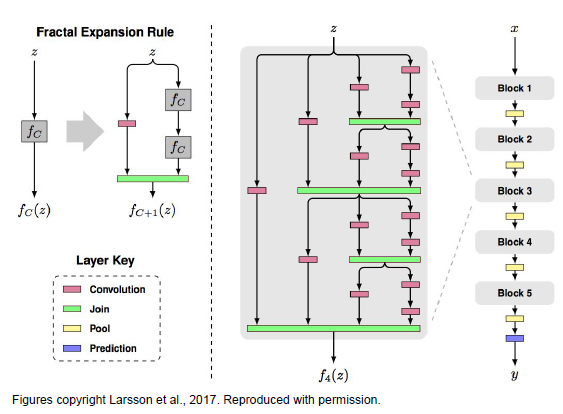
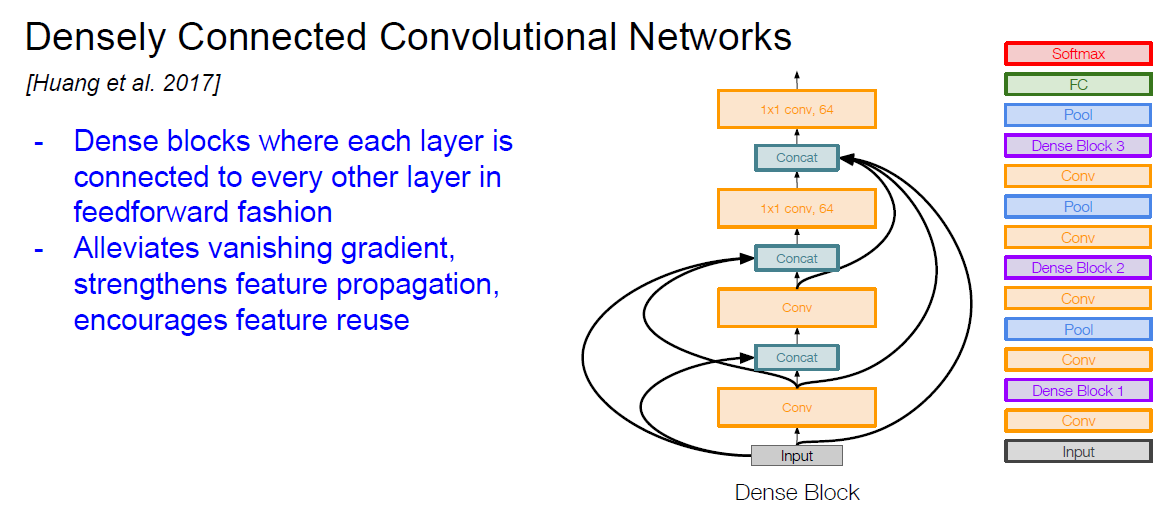
DensNet
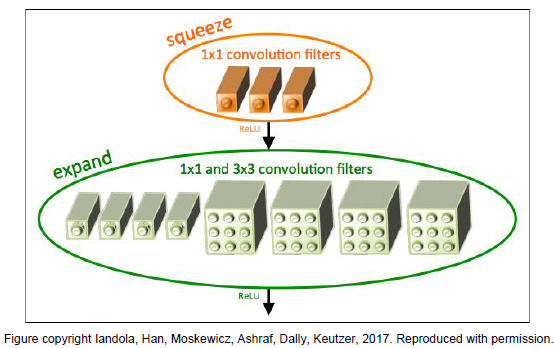
SqueezeNet